Casetextは「Google類似画像検索」ライクな判例リサーチツール
膨大な判例データベースをキーワード検索できるようにしただけでなく、アップロードした判例を読み取り、それに似た文脈を持った判例をピンポイントで探し出してくれるAIエンジンを搭載しているのが、Casetextです。
判例検索サービスの課題「プロでなければ探せない」「利用料が高額」を解決
Casetextは、一言で言えば判例データベース・サービスです。
これまで、判例データベースを使えるのは、現実的には弁護士やリサーチャーなどの専門職に限られていた と思います。なぜなら、
- 裁判や法令の知識がないと、そもそもどんなキーワードで検索すれば欲しい判例情報を探せるのかわからない
- キーワードに判例がヒットしたとしても、それが自身の立場に合った(参考にしてよい)判例なのかを読み取ることが難しい
からです。
加えて、そうした 専門職向けのプロダクトということもあって利用料も高額 であり、大きな法律事務所、大企業の法務部門や大学図書館でもなければ利用できないリソースでした。
このような問題点を、AIを使いすべて解決してしまった革命的なツールが、今回紹介するCasetextです。
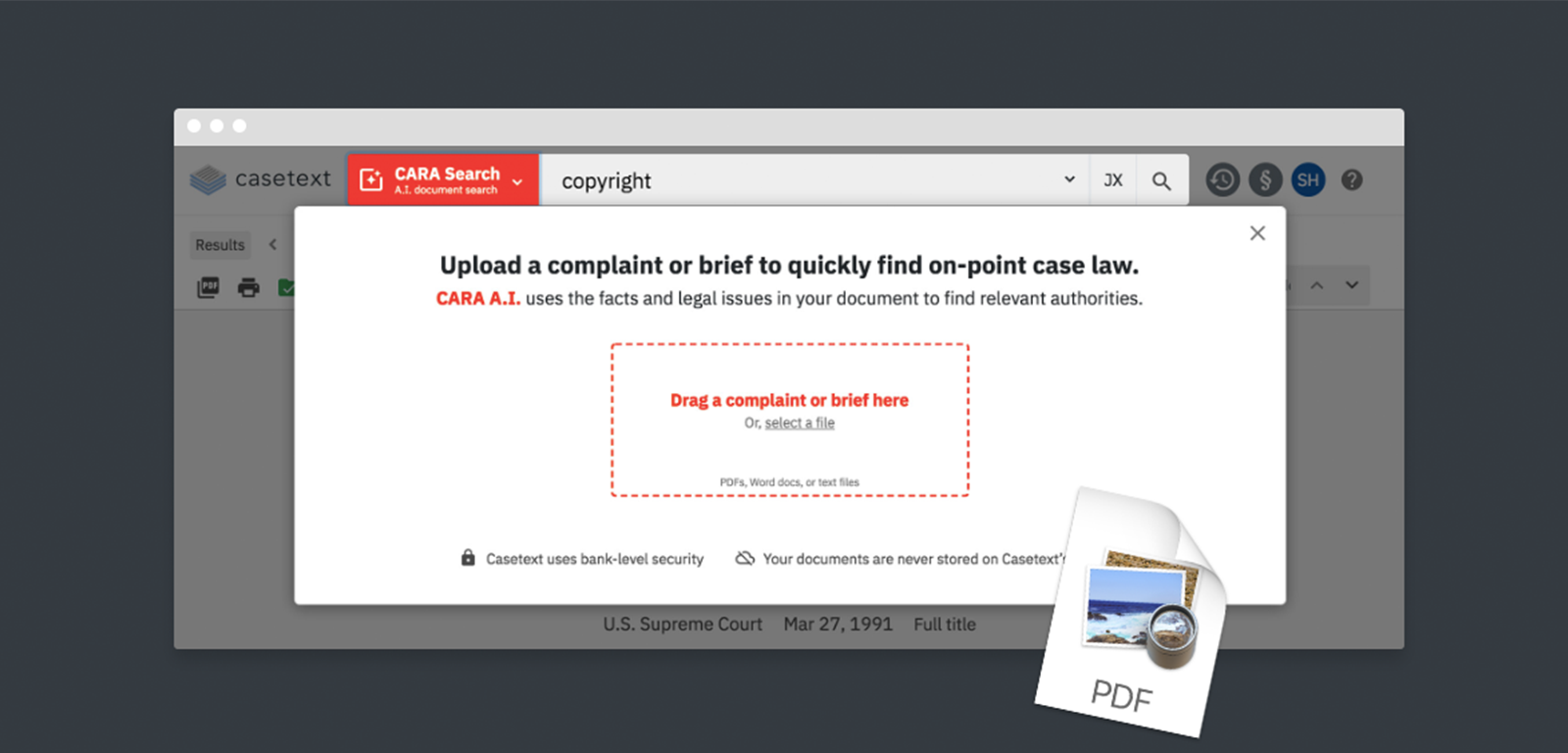
使い方も仕組みもGoogle類似画像検索そのもの
このリーガルテックサービスでは、ユーザーがアップロードした判例を読み取り、そのシチュエーションや文脈を解析して、それに似た別の判例を探し当ててくる、というところに「CARA」と名付けられたAIを用いています。
たとえばここに、「信義を尽くし誠実に交渉する」というかなり抽象的な義務を定めた契約条項を有効と判断し損害賠償請求が認められた、85ページにおよぶデラウエア州の最高裁判決があります。

これを、Casetextにドラッグ&ドロップしてアップロードするだけで、似たようなシチュエーションで争われた判例が検索結果に並ぶ、というわけです。もちろんキーワードをさらに限定的にしたり、裁判所のレベル、原告被告の業界、判決が出た年で検索結果を絞り込むといったこともできます。しかしそれをしなくても、テキスト検索では絞り切れないような大量の判例データベースから、参考になる判例だけをピンポイントで見つけることができます。
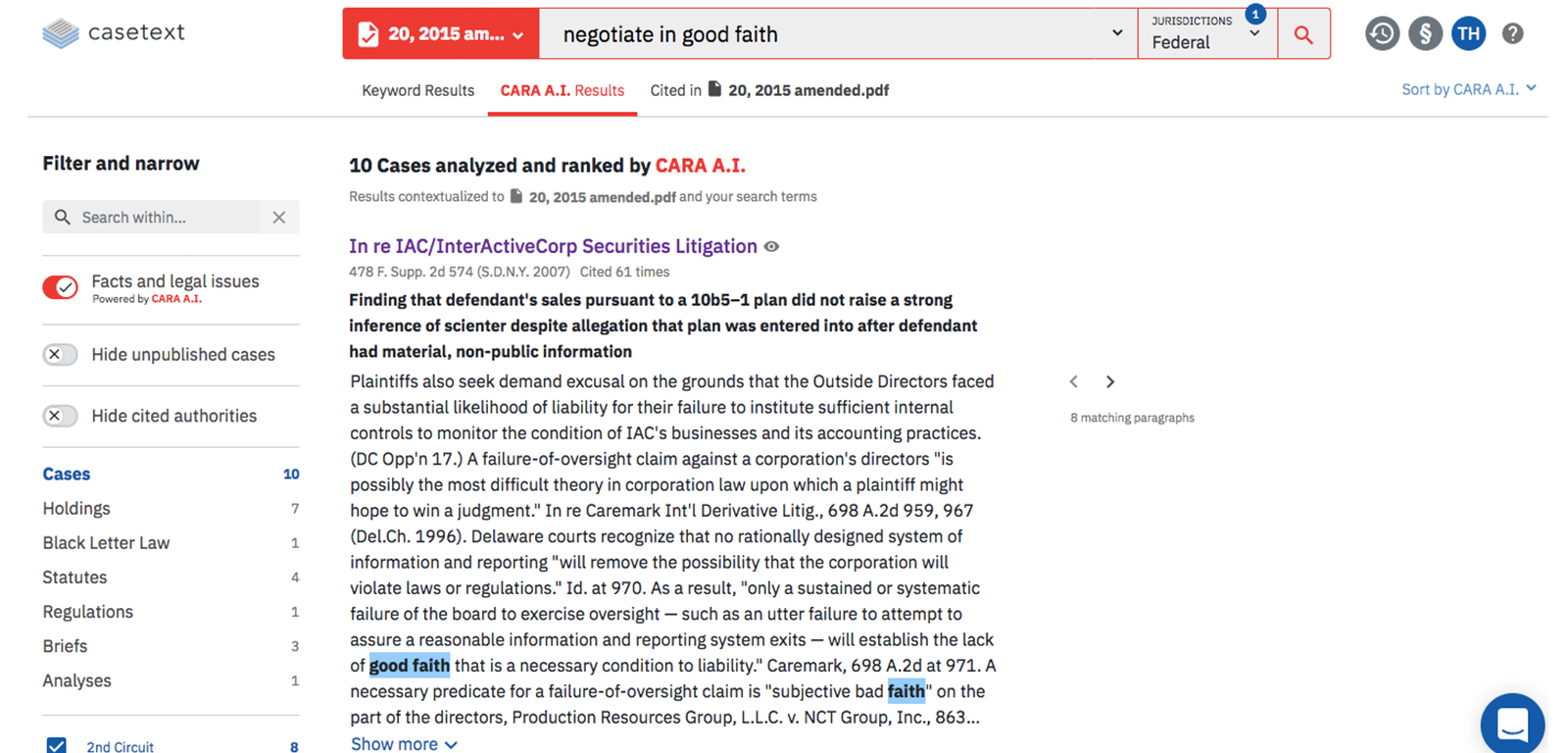
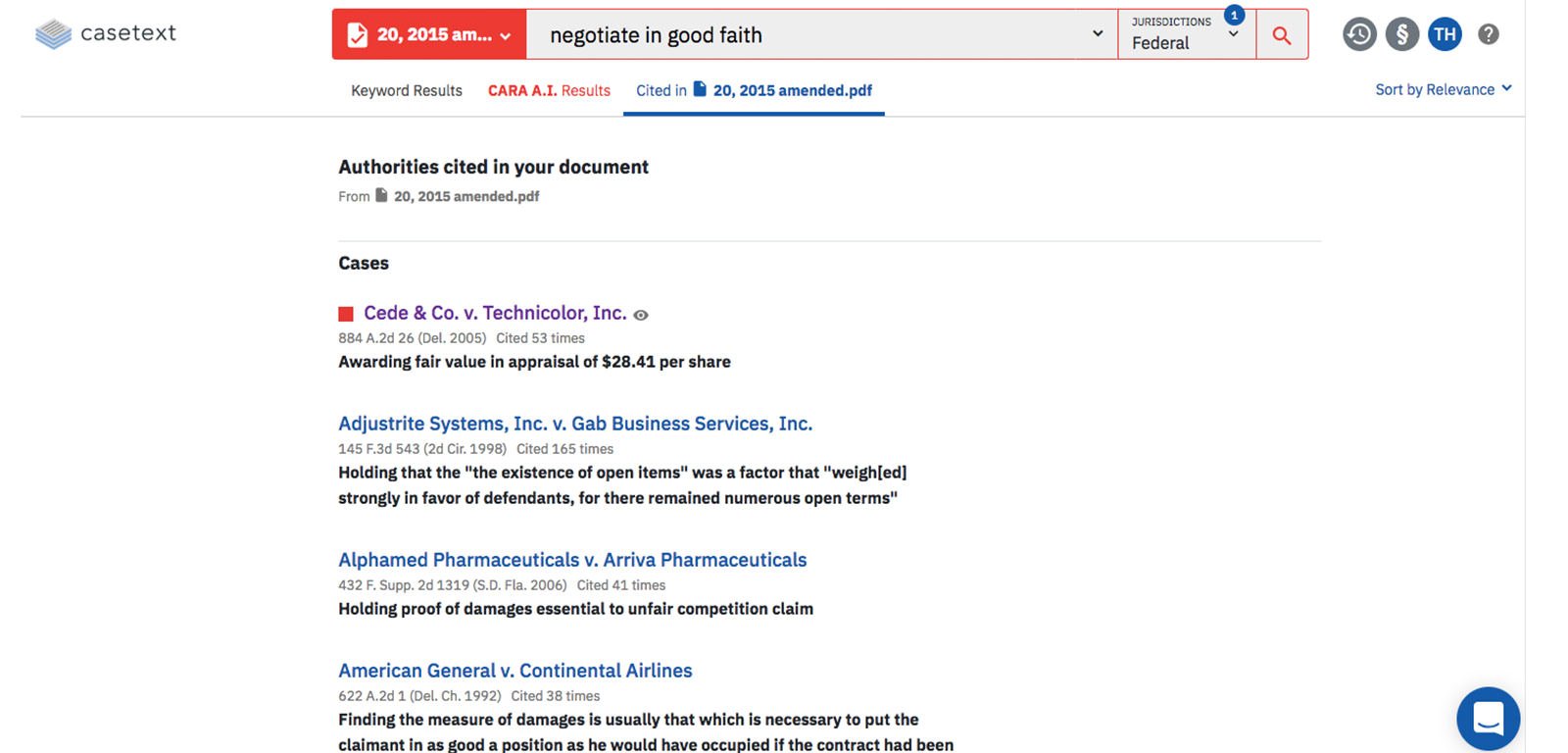
AIがどのように文脈を読んでいるのか、開発者のインタビュー等を見ても当然に明らかにはされていないのですが、Casetextにはアップロードした判例の中で引用されている別の判例をリストアップしてくれる機能があります(以下スクリーンショット)。これを見ていると、この引用された判例との共通点を読み取っているのではないか、という気がします。
それはさておき、Casetextのこのユーザーエクスペリエンスは何かに似ているよな…としばらく考えていたのですが、ひらめいたのが、Googleの類似画像検索そのもの だなあと。
人間が画像を見て言語化(キーワード化)するのは難しい。それなら、人間にはほしい画像をアップロードさせて、その画像をAIで解析して似た要素を持つ画像を持ってこよう。まさにそれと同じことを、判例検索という専門的な分野でできるようにしたのが、このCasetextというわけです。
ちなみに、2018年12月に開催されたウェビナー(ウェブセミナー)では、シンガーソングライターのマイリー・サイラスが著作権侵害で訴えられ被告となった判例をアップロードすると、10秒もかからずにアッシャーが著作権侵害で訴えられ被告となった判例がAI検索のトップヒットに上がる、という事例を実演していました。
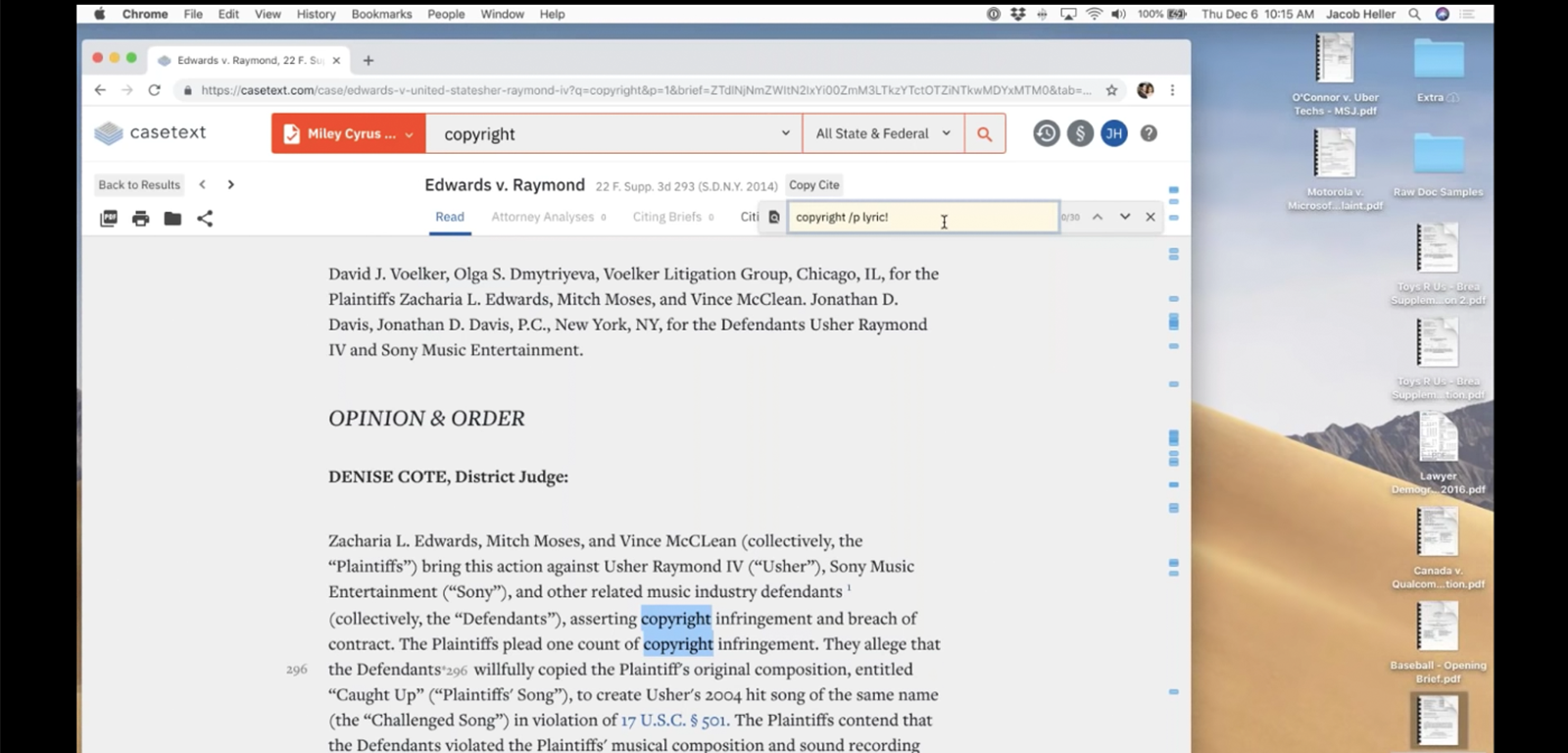
つまり、ともに著名アーティストが被告となり同じような論点が争われた事件を、ファイルをアップロードしただけで一瞬でサクッと検索できたというわけです。もはやリーガルリサーチはプロでなくても、そしてプロであっても絶対かなわないスピードでできてしまう未来が来てしまった のだなと実感します。
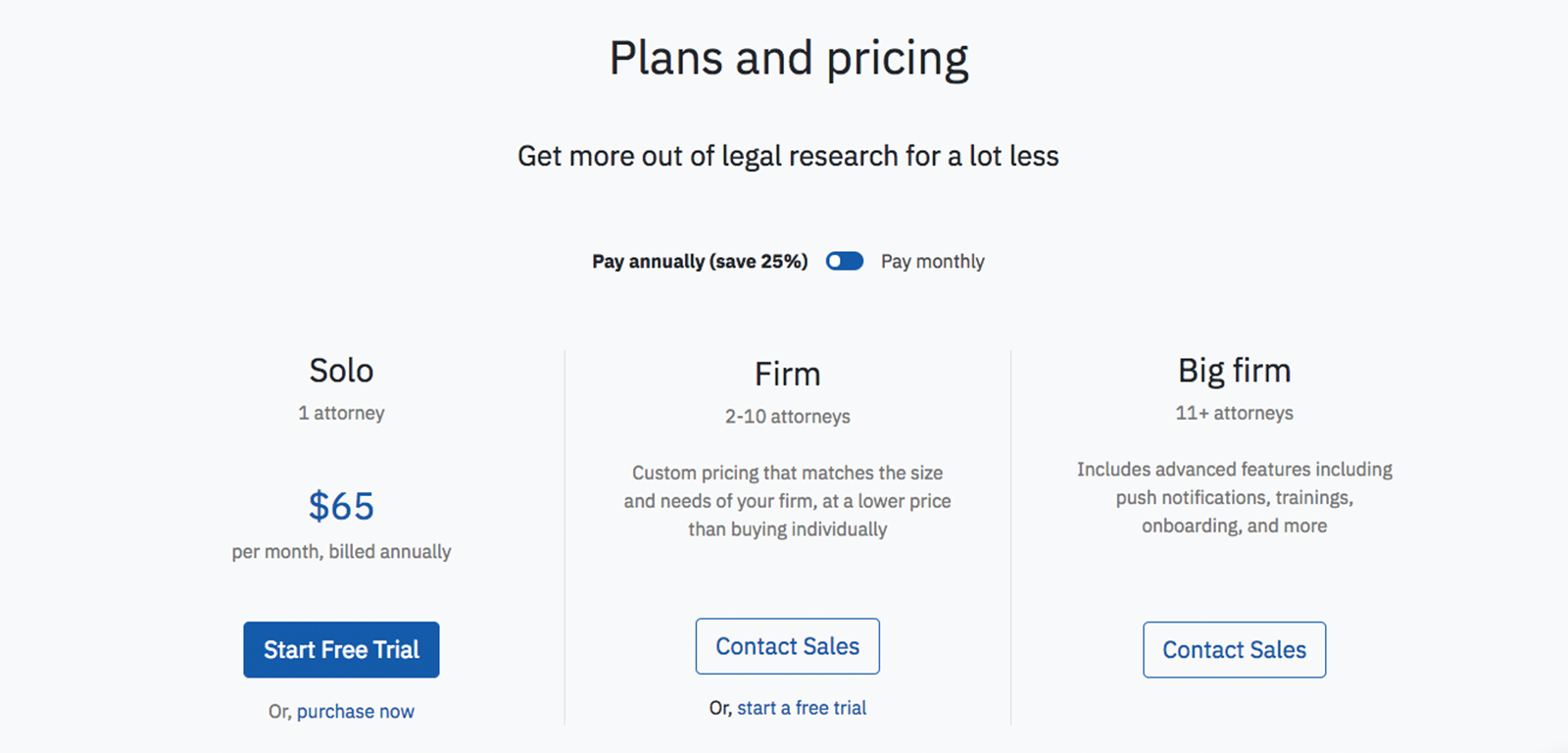
利用料は個人利用ならひと月65ドルから
これまで、こうした判例データベースシステムは、大手出版社が高額な値付けをして大手法律事務所や企業に売り込むというものというのが常識で、機能的にもキーワード検索に毛が生えたようなものにもかかわらず、その利用料は月数百ドルは下らないものでした。
Casetextは、AIでこれを革命的に使いやすくしただけでなく、「法律情報へのアクセスを広げたい」という思いから価格破壊にもチャレンジ。個人での利用であれば月65ドルから利用可能 となっています。
米国では、判例がテキストデータ(PDF)で積極的に公開されてきたことで価値あるビッグデータとして活用され、こうしたAIエンジンも発達しやすかったという背景がありました。
日本では、判例情報のテキストデータ自体が全判決の1%にも満たない割合しか公開されていないという、「もっと手前の課題」があります。日本としても裁判のIT化の議論は進められていますが、判決の公開については、そもそも裁判手続きがペーパーベースであったという課題に加え、プライバシーや営業秘密の問題が懸念され、残念ながらすぐに実現される見込みはありません。
一方で、こうしたAIエンジンがここまで実用化されているのを実際に見ると、そんな悠長なことをやっていてよいのだろうかと、疑問を感じるところです。
(橋詰)
この記事をシェアする


